YOLO
Yolo
Faster-RCNN은 multi object detection문제를 풀기 위한 모델을 제시한 논문이다. 이 문제를 푸는 방법은 이전에도 RCNN, SPNN, Fast-RCNN이 존재했지만 속도와 계산 비용에 문제점이 있었고, 논문에서는 이를 개선하기 위한 모델을 제시한다.
위에 언급된 이전 방법들과 이 논문에서 제시하는 방법 모두 문제를 풀기 위한 공통된 두 단계로 이루어져 있다. 먼저 이미지에서 객체가 있을만한 곳을 고르는 단계(region proposal)와 그 다음 골라진 영역을 cnn 네트워크를 사용하여 객체가 있는지, 있다면 어떤객체가 있는지 살피는 (detection) 단계이다.
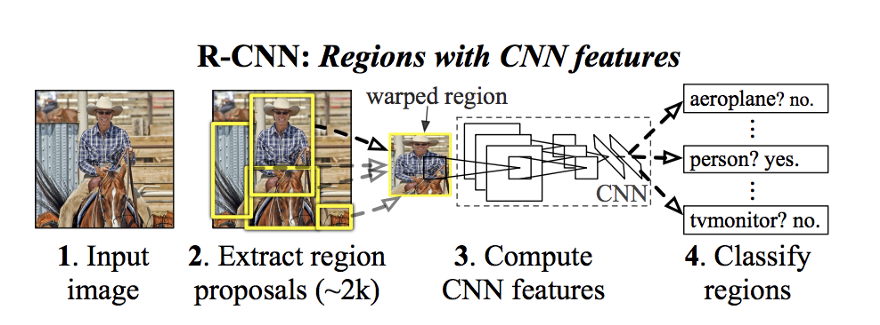 RCNN은 최초로 multi image detection 분야에서 괜찮은 성과를 나타낸 논문이다. 하지만 region을 고르고 그것을 검사하기 위한 두 방법 모두에 많은 계산이 필요했다.
RCNN에서는 resgion proposal을 위해 Selective Search 등의 머신러닝 방법을 통해 이미지 내에서 가능한 모든 영역(한 이미지당 2000개 정도)을 고르고,
detection을 위해 proposed 된 각각의 영역마다 이미지를 cnn네트워크에 통과해 해당 영역에 무엇이 있는지 살핀다.
이 방법으로는 GPU를 이용해도 한 이미지의 전체 객체를 검출하는데 47초가 걸리므로 리얼타임으로 구현될 수 없었다.
RCNN은 최초로 multi image detection 분야에서 괜찮은 성과를 나타낸 논문이다. 하지만 region을 고르고 그것을 검사하기 위한 두 방법 모두에 많은 계산이 필요했다.
RCNN에서는 resgion proposal을 위해 Selective Search 등의 머신러닝 방법을 통해 이미지 내에서 가능한 모든 영역(한 이미지당 2000개 정도)을 고르고,
detection을 위해 proposed 된 각각의 영역마다 이미지를 cnn네트워크에 통과해 해당 영역에 무엇이 있는지 살핀다.
이 방법으로는 GPU를 이용해도 한 이미지의 전체 객체를 검출하는데 47초가 걸리므로 리얼타임으로 구현될 수 없었다.
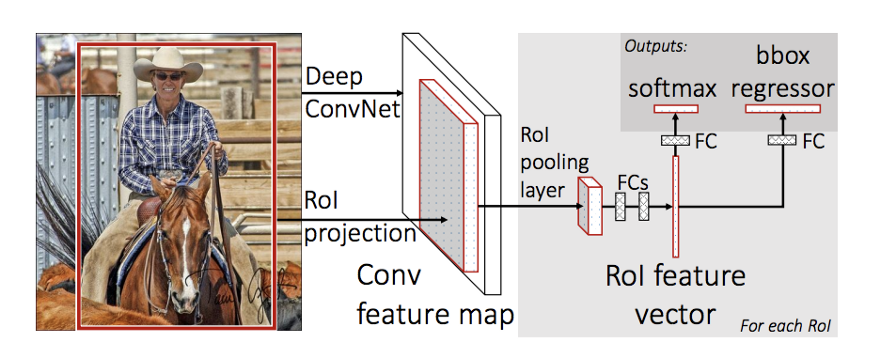 Fast-RCNN은 RCNN의 비효율성을 개선한 논문이다. RCNN에서는 2000개 정도의 region proposal된 영역을 각각 CNN 네트워크를 통과했다.
하지만 2000개 중 대부분의 영역이 아래 그림처럼 이미지상에서 겹쳐지는 영역일 것이다.
Fast-RCNN은 RCNN의 비효율성을 개선한 논문이다. RCNN에서는 2000개 정도의 region proposal된 영역을 각각 CNN 네트워크를 통과했다.
하지만 2000개 중 대부분의 영역이 아래 그림처럼 이미지상에서 겹쳐지는 영역일 것이다.

Fast-RCNN에서는 이 부분에 집중해 원본 이미지 전체를 한 번만 CNN네트워크에 통과하고, region proposal 된 영역을 이미 뽑힌 Feature map 영역에서 잘라서 사용한다.
Fast-RCNN을 이용하면 47초가 걸리던 문제를 2초대에 풀 수 있다.
Fast-RCNN은 RCNN의 detection network의 중복 문제를 해결하면서 분명 많은 시간을 개선할 수 있었다. 하지만 region proposal을 위해서는 여전히 Selective-Search 등 머신러닝 알고리즘 방식을 사용하고 있었고 이 부분은 새로운 bottle-neck이 되었다.
Faster-RCNN은 이름에서 알 수 있듯 Fast-RCNN을 개선한 모델이다. 기존에 머신러닝 알고리즘 방식으로 진행되던 Region Proposal영역에 딥러닝을 도입해 더 효율적, 효과적으로 가능한 영역을 탐색한다. 덕분에 전체 탐색 시간을 이전 모델에 비해 10배정도 빨라진 0.2초로 낮추었다.
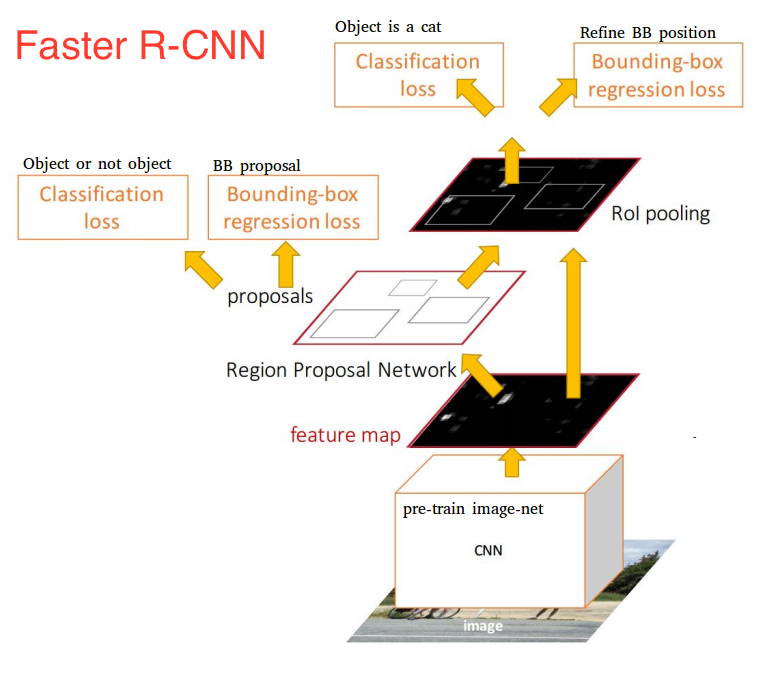
모델 구조는 역시 multi object detection 문제를 위해 두가지 부분으로 나뉘는데, 이미지의 가능한 영역을 탐색하는 RPN module과 이를 이용해 객체를 탐색하는 detection network 영역이다.
논문에서는 RPN과 detection 모두에 딥러닝 방식을 사용하기 때문에 두 영역을 하나의 구조로 합칠 수 있었다. 위 그림에서처럼 base network (shared network)를 정의하고, 해당 base network에서 뽑힌 feature를 바탕으로 RPN과 detection을 이용한다. base network를 공유함으로써 RPN을 위한 시간의 한계비용을 한 이미지당 10ms 정도로 상당히 낮출 수 있었다.
base network로는 VGG나 ZF 네트워크를 사용한다.
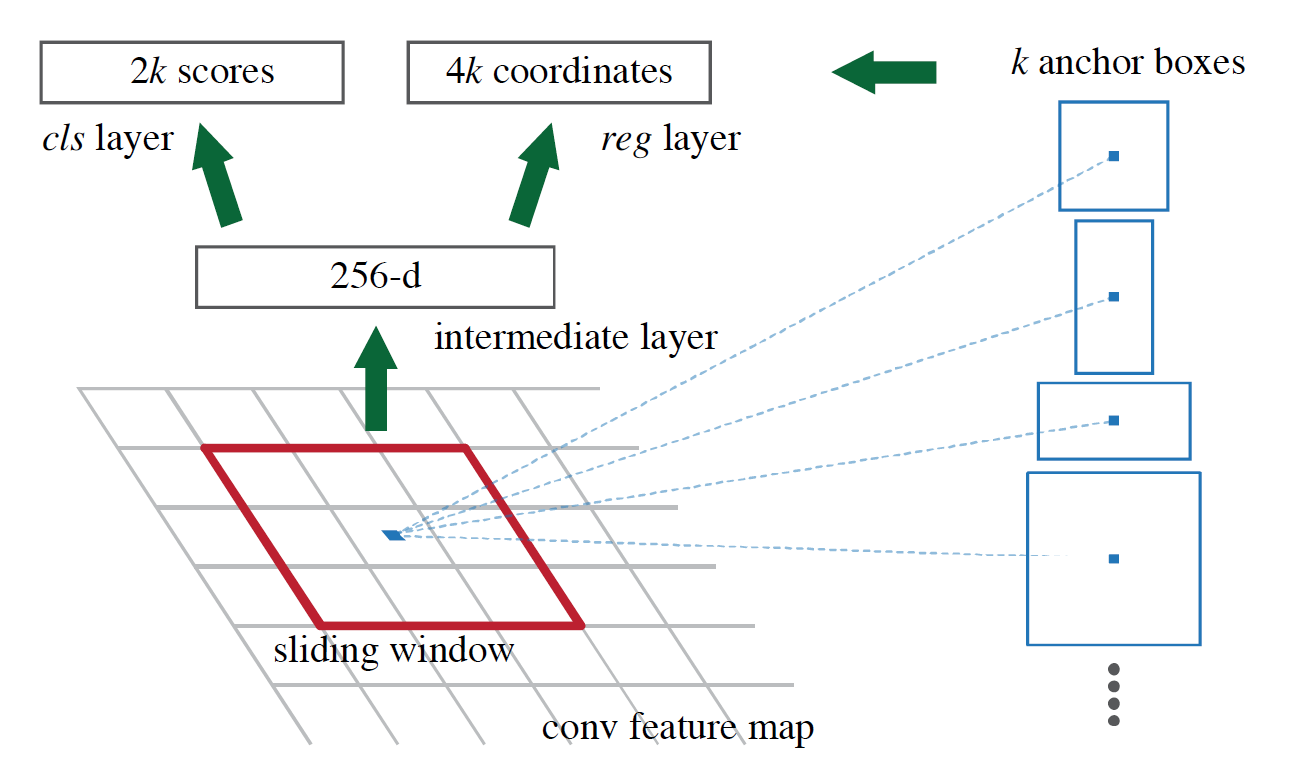
이 논문의 가장 큰 contribution인 RPN 모듈은 이미지에서 가능한 영역을 골라내는 region proposal 역할을 하는 네트워크다. 이 네트워크는 base network feature map의 NxN 영역을 입력으로 받아서 해당 영역이 객체인지 배경인지, 객체라면 어떻게 해당 객체에 맞게 bound box의 크기와 scale을 조정할지 결정한다.
이 과정은 위 그림에 표현되어 있다. 먼저 NxN영역을 center로 하는 anchor를 뽑는다. anchor는 현재 살피고 있는 NxN 영역의 중앙을 센터로하는 다양한 크기와 모양의 후보 영역이다. 논문에서 anchor의 개수는 k로 표현되는데, RPN 네트워크는 k개의 anchor 영역 각각에 대해 객체인지 배경인지 (cls layer), 객체라면 어떻게 해당 객체에 맞게 bound box(anchor)의 크기와 scale을 조정 (reg layer)할지 결정한다.
cls layer는 NxN영역마다 k개의 anchor 각각에 대해 True/False를 결정하기 때문에 2k의 아웃풋을 갖고, reg layer에서는 anchor마다 center 좌표, 가로 세로 길이를 결정하기 때문에 4k의 아웃풋을 가진다. 따라서 RPN은 하나의 NxN영역에 대해 6k의 아웃풋을 갖는다.
한 이미지당 256개의 anchor를 랜덤하게 뽑아 학습한다. 이때 대부분의 anchor는 실제로 객체 영역이 아닌 배경 영역일 것이기 때문에 실제 이미지에서 배경 영역의 anchor와 객체 영역의 anchor를 1:1 비율, 즉 128개씩 랜덤으로 뽑아서 사용한다. 만약 객체 영역의 anchor가 128개가 안되는 경우에는 배경 영역의 anchor를 사용해서 채운다.
Faster-RCNN의 detection network는 fast rcnn의 detection network를 그대로 사용한다. RPN에서 추천된 anchor들은 크기가 다양하기 때문에 detection network의 FCN에서 사용하기 위해 ROI Pooling을 이용해 하나의 크기로 맞춘다.
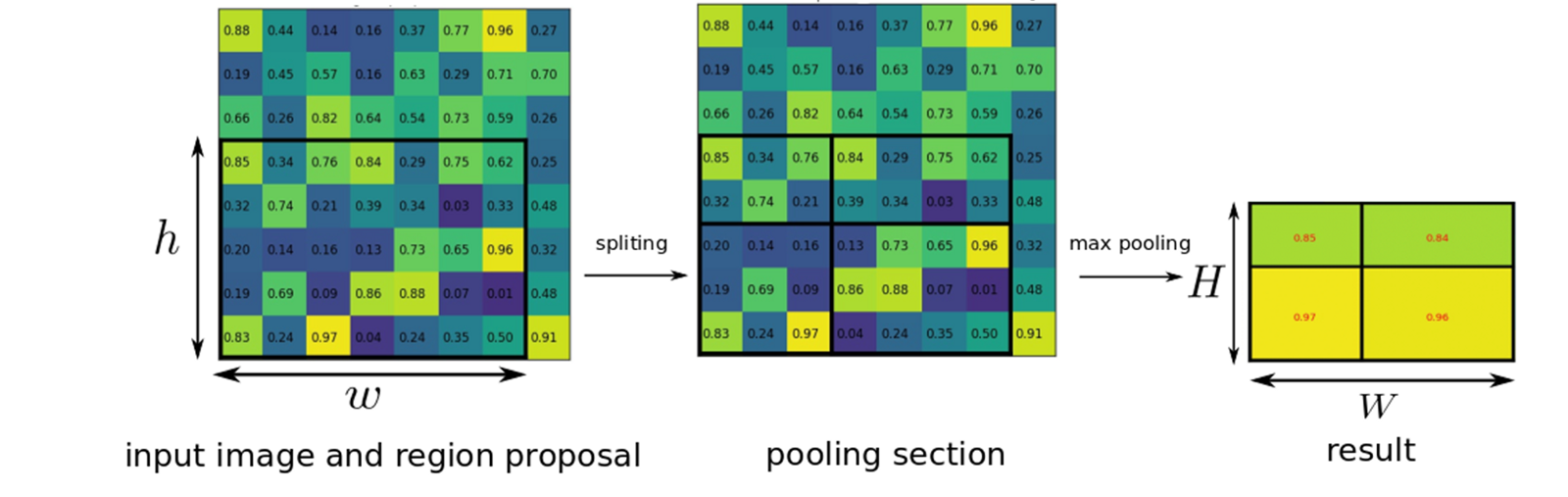
ROI풀링을 통해 크기가 같아진 region들은 detection 네트워크를 통해 각각 다시한번 객체인지 배경인지, 객체라면 어떻게 해당 객체에 맞게 bound box의 크기와 scale을 조정할지 결정된다.
Faster-RCNN의 학습은 RPN, Detection Network, Base Layer를 조합하여 반복적으로 학습한다.
1. pretrained된 네트워크로 초기화된 RPN 학습 (pretrained도 학습)
2. pretrained된 네트워크(base network)로 초기화된 detection network 학습 (이 때 trained network는 RPN에서와 다름, 즉 shared network 아님)
3. 2번에서 사용된 base network를 이용해 RPN을 학습 (pretrained 고정)
4. 3번에서 학습된 RPN과 2번의 base network를 이용해 detection network를 학습 (pretrained 고정)
Yolo
1. Introduction Faster-RCNN은 multi object detection문제를 풀기 위한 모델을 제시한 논문이다. 이 문제를 푸는 방법은 이전에도 RCNN, SPNN, Fast-RCNN이 존재했지만 속도와 계산 비용에 문제점이 있었고, 논문에서는 이를 개선하기 ...
Region with CNN features
블로그 포스팅하기